
Hoje estava conversando com o Guilherme Simões, o meu sócio na FATTO. Então, ele me comentou de uma licitação para medição em pontos de função. O preço vencedor foi de R$ 3,63 por Ponto de Função. Ou seja, a empresa faturará R$ 3.630,00 (brutos) para medir o equivalente a umas 12.000 horas-homem de desenvolvimento sem qualquer automação na medição.
O benefício, que paga o esforço de medição
Antes de tudo, deve-se ressaltar que medir em pontos de função exige interpretar as diferentes representações do software com o objetivo de depreender a Visão do Usuário. Portanto, o investimento se paga com o desenvolvedor perdendo a capacidade de fabricar pontos ao contrário de outras métricas.
Por exemplo, se uma mesma funcionalidade pode ser descrita por duas histórias de usuário e o objeto de medição são as histórias de usuário, então basta o desenvolvedor especificar mais histórias de usuário para maximizar o que recebe sem reflexo na sua entrega para o negócio. Da mesma forma, se o objeto da medição são programas ou linhas de código.
A medição em Pontos de Função desloca o esforço de desenvolvimento para o atendimento das necessidades de negócio, porque o esforço de medição coloca quem define os fluxos operacionais do negócio como aquele capaz de criar pontos.
Automação da medição e outros fatores de menor esforço / custo
Quais as soluções para viabilizar um preço como esse para a realização de um trabalho como a medição de pontos de função?
Primeiro, a automação, ainda que parcial, no processo de contagem. Por exemplo, por meio de redes neurais e sistemas especialistas. Em seguida, pela utilização de especificações funcionais de maior qualidade. Por fim, com. redução no custo da mão de obra de profissionais CFPS.
Sobre o custo da mão de obra, vivemos a época de “The Great Resignation“. Então, todas as empresas estão se reinventando para manter e desenvolver novos talentos. No entanto, isso não reduz do custo de mão de obra. Muito pelo contrário.
Sobre as especificações de maior qualidade, a situação é exatamente o oposto. Portanto, a informação disponível para medição exige cada dia maior esforço para se “descobrir” os requisitos.
Por fim, a automação da medição está engatinhando. Estamos na FATTO com algumas iniciativas a partir de medições com o MESUR. No entanto, não há nada liberado ainda.
Sem automação da medição, o barato sai caro
Se a medição perde esse papel de obter a “Visão do Usuário”, então a consequência é medir 2 PF ao invés de 1 PF. Esqueça-se da medição por um instante e pense que o custo do desenvolvimento deveria representar cerca de 50 vezes o custo da medição!

Uma solução de automação da medição (contém ironia)
Por isso, investiguei algumas outras alternativas e achei uma solução, cujo investimento é de R$ 59,80 para aquisição dos dados de RPG!
Solução de automação da medição para otimizar a medição, mantendo seus benefícios
Eu passei por aqui para compartilhar uma história onde você mantem os benefícios de uma medição da produção com base em um padrão internacional com a sua automação e sem necessitar ficar refém da própria sorte.
Espero que seja útil para inspirá-lo em usos criativos dos padrões de mercado. Espero que ajude você a obter ganhos de produtividade na medição concretos. E, que pela compra da ilusão da economia na medição (1% ou 2% do processo), você não veja efeitos negativos nos 100% do desenvolvimento que muito (mas muito) superem essa economia.
Segue a minha história.
Produção de componentes de interface com o usuário
Você mantém uma equipe especificamente para o desenvolvimento, customização e manutenção de componentes Angular para o seu front-end.
Sem dúvida, componentes podem ser medidos em uma perspectiva funcional usando pontos de função. Mas considerando que os índices de produtividade para esse tipo de trabalho são incomparáveis com os índices de produtividade no desenvolvimento de aplicações e o processo é essencialmente manual, qual a alternativa? Contar linhas de código? Certamente, não.
Esse foi o desafio com o qual nos deparamos. Nessa busca, avaliamos as soluções existentes, sua aplicabilidade e que partes de sua definição tem potencial de aproveitamento. Nesse sentido, avaliaram-se os seguintes métodos:
- Análise de Pontos de Função do Grupo Internacional de Usuários de Pontos de Função (IFPUG);
- Análise de Pontos de Função do Consórcio Internacional de Medição de Software em Geral (COSMIC);
- Processo de Avaliação de Requisitos não Funcionais do IFPUG (SNAP);
A seguir, sintetizam-se as conclusões e o encaminhamento dado a partir da análise de cada método.
Pontos de Função IFPUG
Descartou-se seu uso, porque:
- Não havia documentação dos requisitos funcionais dos componentes, que permita a sua aplicação nos moldes usados nos demais desenvolvimentos no cliente;
- A medição em pontos de função promoveria sobrecarga no esforço do desenvolvedor e do medidor na “engenharia reversa” dos requisitos funcionais a partir de elementos da implementação com alto grau de subjetividade.
- Empiricamente se percebeu pouco nexo entre os elementos medidos pela Análise de Pontos de Função e os fatores de custo no desenvolvimento dos componentes.
- Ainda que se optasse por essa solução, seria necessário derivar um índice de produtividade próprio na medida que não se trata do mesmo processo ou tecnologia dos demais desenvolvimentos medidos em pontos de função no cliente.
Pontos de Função COSMIC
Além de compartilhar os motivos destacados anteriormente, descartou-se seu uso, porque:
- Os movimentos de dados, medidos pelo COSMIC, exigem um mapeamento manual dos elementos da interface com o usuário;
- O esquema de quantificação das mudanças em elementos da interface com o usuário do COSMIC produz o mesmo resultado independentemente da dimensão dessas mudanças em um mesmo movimento de dados.
- O desenho do método não é integrado à cultura de medição em uso no cliente ou nas Fábricas de Software que a atendem.
SNAP – Processo de Avaliação de Requisitos Não Funcionais de Software
O SNAP foi selecionado como base para a solução de medição, porque:
- Possui completa integração do SNAP com a APF, ambos do IFPUG e cujos componentes de medição são conhecidos tantos pelo cliente quanto pelas fábricas de software contratadas;
- Desenho flexível, que permite a sua adoção parcial conforme a adequação de suas 14 subcategorias de medição às necessidades de medição do cliente;
- Histórico de utilização parcial prévia no âmbito do Governo Federal; em especial a Caixa Econômica Federal;
- Possibilidade de definição de heurísticas e premissas de medição facilitando a automação a partir de produtos da Gestão de Configuração de Mudança em uso no ambiente de desenvolvimento dos componentes; em especial, o GitHub.
Portanto, a solução de medição não se utiliza do SNAP propriamente dito; mas o utiliza como um framework na automação da medição dos resultados entregues demonstrados pela diferença no código (diff) antes e depois do desenvolvimento medido.
Insumos usados no levantamento de dados para automação da medição
O levantamento de dados para análise da solução coletou as seguintes informações:
• Planilha com o esforço informado pela Fábrica de Software e aceita pelo cliente do desenvolvimento de 24 componentes;
• Arquivos extraídos do GitHub com as mudanças introduzidas pela Fábrica de Software correspondentes ao esforço indicado anteriormente.
Adicionalmente, realizaram-se entrevistas com os especialistas da Fábrica de Software no entendimento do processo de desenvolvimento dos componentes.
Mapeamento para o SNAP a partir da análise dos dados
A solução de medição descrita se baseia no SNAP e utiliza as subcategorias:
- Validação de Entrada de Dados (SC 1.1);
- Interfaces do Usuário (SC 2.1);
- Métodos de Ajuda (SC 2.2).
A partir do levantamento de dados, estabeleceu-se uma série de uma série de heurísticas e premissas para mapear a informação disponível sobre os resultados entregues pela fábrica de software para o framework de medição do SNAP. A seguir, descrevem-se essas heurísticas e premissas para cada subcategoria do SNAP.
SC 1.1 – Validação de Entrada de Dados
Assume-se:
- Uma única unidade de contagem SNAP (SCU) para cada componente, porque no desenvolvimento do componente não se consideram quantos ou quais são os processos elementares no qual ele será utilizado.
- Cada item de validação no código de teste é mapeado para um campo (TD) sendo validado.
- O número de validações condicionais na maior cadeia de validação (combinado de if-else, loops de while ou for, ou qualquer outro bloco de validação) é definido na primeira faixa de complexidade; ou seja, entre 1 e 2.
SC 2.1 – Interfaces do Usuário
Assume-se:
- Uma única unidade de contagem SNAP (SCU) para cada componente, porque no desenvolvimento do componente não se consideram quantos ou quais são os processos elementares no qual ele será utilizado.
- Cada propriedade única especificada no CSS no computo da quantidade de propriedade incluídas ou configuradas;
- Cada região mais externa do CSS no computo da quantidade de elementos de UI Únicos;
SC 2.2 – Métodos de Ajuda
Assume-se:
- Um objeto de ajuda para cada ToolTip.
- página sobre o componente como o equivalente a uma imagem de tela.
Automação da medição
Um script em Python analisa os arquivos de diff gerados pelo GitHub e gera uma planilha de medição com a contagem como descrito anteriormente.
Avaliação da correlação
Em estatística, o coeficiente de correlação r mede a força e a direção de uma relação linear (proporcional) entre duas variáveis. O valor de r está sempre entre +1 e -1. O valor de r 1 indica uma proporcionalidade perfeita entre duas variáveis; ou seja, qua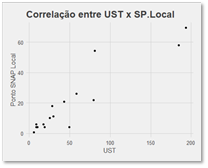 nto mais uma sobe, mais a outra também sobe proporcionalmente. E o valor de r em -1 para e indica uma proporcionalidade inversa perfeita; ou seja, se uma sobe a outra diminui proporcionalmente.
nto mais uma sobe, mais a outra também sobe proporcionalmente. E o valor de r em -1 para e indica uma proporcionalidade inversa perfeita; ou seja, se uma sobe a outra diminui proporcionalmente.
Utiliza-se o teste de correlação de produto-momento de Pearson nesta avaliação.
A hipótese de correlação entre a variação da medição em UST e a medição proposta em SNAP points foi suportada. A medição em UST se correlaciona de maneira estatisticamente significativa com a medição proposta em SNAP points com um Test Score, r (20) = 0.9327542, p ≤ 5%.
Regressão Linear
Em estatística ou econometria, regressão linear é uma equação para se estimar a condicional (valor esperado) de uma variável y, dados os valores de algumas outras variáveis x. No caso, estimar a quantidade de UST a partir de uma medição de Pontos SNAP conforme descrito neste documento, denominado SP Local. Ou seja, calibrar a Taxa de Entrega expressa em UST / SP Local. A partir disso derivar o equivalente em PF / SP Local considerando a premissa pactuada na contratação de UST / PF.
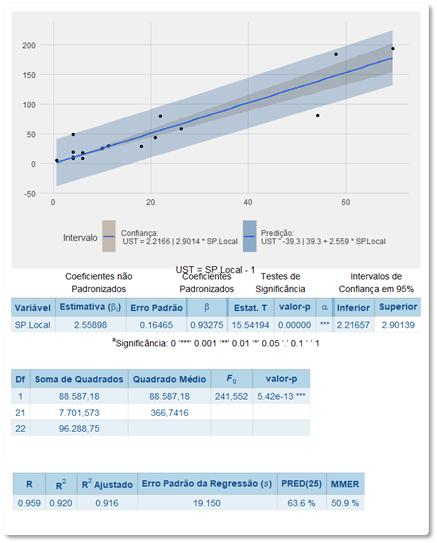
Apesar da primeira regressão ter se revelado estatisticamente significativa e apresentar um coeficiente de determinação adequado, os diagnósticos da análise de resíduos apontaram para 03 casos como valores influentes pela distância de Cook e pelo método DFFIT.
Os mesmos casos também foram apontados como valores extremos ou outliers acima de dois desvios padrão studentizados.
Enquanto para 02 componentes se obtiveram respostas sobre o porquê de uma produtividade mais baixa em relação aos demais, o mesmo não se obteve em relação a um deles e foi removido do estudo.
Análise de Variância (ANOVA)
A regressão linear foi calculada para prever a quantidade de UST baseada na quantidade de Pontos SNAP Locais. Uma equação de regressão significativa estatisticamente foi encontrada [F(1,21) = 241,552, p < .001], com um coeficiente de determinação R2 de 0,92.
O coeficiente de determinação (R2) mede o quanto da variação na quantidade de UST é explicado pela variação da medição dos Pontos SNAP Locais.
A quantidade de UST previstas é igual a 2,55898 x SP Local e SP Local é medido como Pontos SNAP descritos neste documento. Portanto, a quantidade de UST é incrementa em 2,55898 para cada Ponto SNAP medido. Ou seja, a quantidade de Pontos SNAP locais é um preditor significativo da quantidade de UST.
O intervalo de confiança para o coeficiente, que representa a taxa de entrega em UST / Pontos SNAP, é entre 2,21657 UST / SP e 2,90139 UST / SP; ou seja, há 95% de probabilidade da taxa de entrega estar entre estes dois valores.
| Cenário | Taxa de Entrega
UST / SP |
Conversão de SP para PF
PF / SP |
| Regressão | 2,55898 | 0,279792259 |
| Mediana | 2,40000 | 0,262409797 |
| Média Ponderada | 2,65689 | 0,290497028 |
A tabela acima coloca a mediana e a média ponderada a partir da amostra. Chama-se a atenção de que a média ponderada representa o valor exato considerando os dados utilizados, o que não significa a exatidão ao utilizá-la para fins de projeção.


